git init, git add, git commit까지 해주고 나면 현재 지역 저장소가 버전별로 잘 관리되고 있는 상황이다. 나의 컴퓨터에만 소스가 저장되지 않고, 서버 상/온라인 상에 백업&협업을 해줄 수 있도록 원격 저장소에 업로드하자. 가장 대표적인 사이트 GitHub를 사용한다.
GitHub 회원가입 및 레포지터리 생성은 굳이 정리하지 않고 넘어가겠다.
깃허브 레포지터리를 만들었다면, 해당 주소를 복사한 뒤 다음 명령어를 실행한다
git remote add origin 복사한 레포지터리 주소
이 명령은 원격 저장소(remote)에 origin을 추가하겠다고 알려주는 것이다. * 여기서 origin = github 레포주소
* 깃에서는 기본 브랜치를 master라고 하듯, 깃허브에서는 origin이라는 이름으로 레포 주소를 명명한다.
원격 저장소(remote)에 제대로 연결됬는지 확인하려면 다음 명령어를 실행한다.
git remote -v
04-4. 원격 저장소에 올리기 및 내려받기
지역 저장소 -> 원격 저장소 : push
원격 저장소 -> 지역 저장소 : pull
원격 저장소에 파일 올리기 - git push
git push -u origin master (최초 push 때에만)
지역 저장소의 브랜치를 origin(원격 저장소)의 master 브랜치로 푸시하라는 뜻
* -u 옵션 : 지역 저장소의 브랜치를 원격 저장소의 master 브랜치로 연결하기 위한 것으로 맨처음 한번만 사용하면 ok
한번만 연결해준 뒤에는 git push 명령어만으로 쉽게 원격 저장소에 소스를 업로드할 수 있다.
git push
원격 저장소에서 파일 내려받기 - git pull
원격 저장소에 있는 파일이 수정된 경우, 지역 저장소와 원격 저장소의 파일에 차이가 생긴다. 이 때 원격 저장소와 지역 저장소의 상태를 같게 만들기 위해 원격 저장소에서 파일을 가져올 수 있는데, 이것을 pull이라고 한다.
git pull origin master
* 기본 원격 저장소가 origin이고 지역 저장소의 기본 브랜치가 master이기 때문에 git pull만 입력해도 ok
04-5. 깃허브에 SSH 원격 접속하기
* SSH : Secure Shell
아이디와 비밀번호를 통해 인증하는 방법 대신, 프라이빗 키와 퍼블릭 키를 이용하여 현재 사용하고 있는 기기를 깃허브에 인증하는 방식이다.
음... 일단은 이 부분은 넘어가고 싶다 ... 추후 필요하면 다시 정리하자.
05. 깃허브로 협업하기
이 책을 읽게 한 메인 부분이다!
05-1. 여러 컴퓨터에서 원격 저장소 함께 이용하기
원격 저장소 복제하기 - git clone
원격 저장소를 기존에 연결된 지역 저장소 외에 다른 지역 저장소에서 사용하려면 원격 저장소에 담긴 내용 전체를 지역 저장소로 가져와야 한다. 원격 저장소를 지역 저장소로 똑같이 가져오는 것을 복제(clone)한다고 한다.
터미널 창에서 디렉터리를 만들 위치로 이동한 뒤, git_home, git_office 디렉터리에 각각 레포를 복제하자.
git clone 복사한 레포 주소 git_home
git clone 복사한 레포 주소 git_office
이제 개인 컴퓨터(git_home)에서 작업한 내용을 push하게 되면 원격 저장소, git_home 디렉터리에만 최신 소스가 반영되어 있을 것이다. 따라서 회사 컴퓨터(git_office)에서 작업을 하기 전에, 먼저 git pull 명령어를 통해 가장 최신 소스를 가져온 뒤 작업을 진행해야 한다!
하나의 원격 저장소에 둘 이상의 컴퓨터를 연결하여 사용한다면 풀과 푸시를 습관화하자. 그래야 어떤 컴퓨터에서 접속하든 가장 최신 소스를 유지할 수 있다.
05-2. 원격 브랜치 정보 가져오기
git pull 명령어는 원격 저장소의 최신 커밋을 지역 저장소에 합쳐준다. 하지만 최신 커밋을 합치기 전에, 원격 저장소에 어떤 변화가 있었는지 먼저 살펴봐야 한다. 이럴 때는 원격 브랜치에서 정보만 먼저 가져올 수도 있다.
원격 master 브랜치
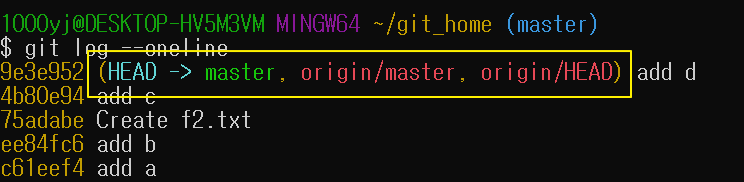
git log --oneline 실행 화면
HEAD -> master : 이 커밋이 지역 저장소의 최종 커밋
origin/master : 원격 저장소의 최종 커밋
git_home 지역저장소에서 f3.txt 파일을 생성 뒤 commit만 해준 상태
지역 저장소의 최종 커밋과 원격 저장소의 최종 커밋이 다른 것을 볼 수 있다. git status를 입력하면 push 명령을 통해 지역 저장소의 커밋을 원격 저장소로 올리라고(publish) 하는 것을 볼 수 있다.
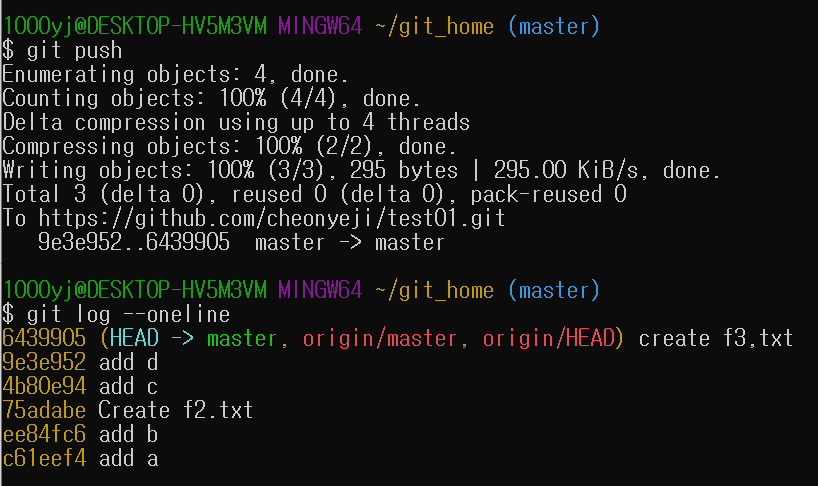
시키는 대로 push를 하고 다시 로그를 찍어보면 다시 지역 저장소와 원격 저장소의 상태가 같은 것을 확인할 수 있다.
HEAD가 가리키는 곳이 원격 저장소, 지역 저장소 둘 다로 같아졌다~!
원격 브랜치 정보 가져오기 - git fetch
git fetch 명령은 원격 저장소의 정보를 가져오는 기능이 있다. 팀 작업을 할 때 다른 사람이 수정한 소스를 한번 훑어보고 지역 저장소와 합치고 싶다면 pull 대신 fetch를 사용하여 커밋을 가져온 뒤 지역 저장소와 합치면 된다.
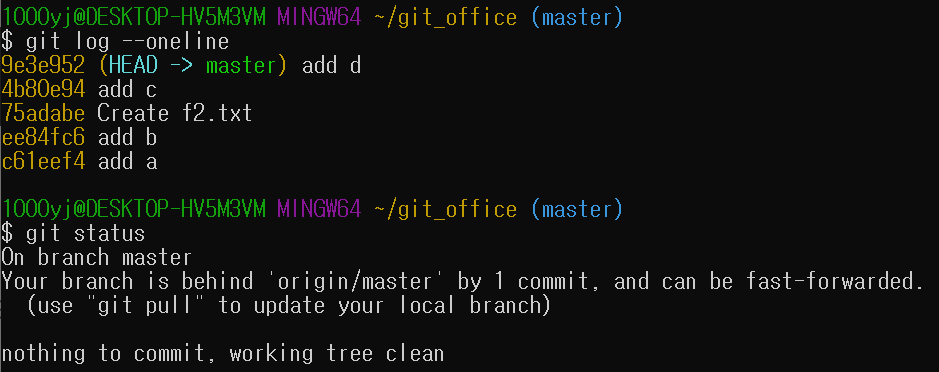
git_office로 이동한 뒤 git fetch 명령을 실행하면 지역 저장소에는 실질적으로 바뀐 것이 아무것도 없다. 로그 역시 변화가 없다. 원격 저장소에 있는 최신 커밋 정보는 가져왔으나 아직 합치지 않았기 때문이다. 따라서 git status 명령을 실행해보면 현재 한개의 커밋이 뒤쳐져 있다고 나온다.
fetch만 실행하고 git status를 찍어본 모습. git pull 명령어를 사용하면 업데이트를 할 수 있다고 친절하게 알려준다.
그렇다면 fetch로 가져온 최신 커밋 정보는 어디에 있을까? 바로 origin/master 브랜치가 아니라, FETCH_HEAD라는 브랜치로 가져온다. 패치해서 가져온 최신 커밋을 살펴보고 싶다면 FETCH_HEAD 브랜치로 checkout해서 살펴보면 된다.
git checkout FETCH_HEAD
git log
fetch한 후 최신 커밋을 현재 브랜치에 합치려면 git pull 명령어를 사용하여 원격 저장소의 소스를 내려받을 수도 있고, git merge 명령어로 FETCH_HEAD에 있던 커밋을 병합할 수도 있다. git merge를 사용해보자!
git checkout master
git merge FETCH_HEAD
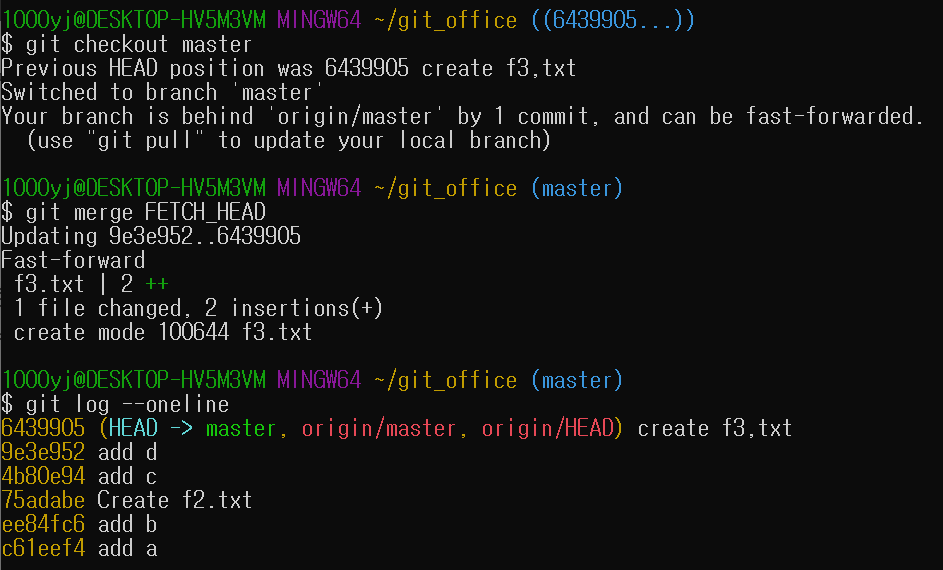
merge로 최신 커밋을 가져온 모습
* fetch한 뒤 merge 할 때 git merge origin/master 나 git merge origin/브랜치명 을 적어 커밋할 수 있다. 하지만 매번 브랜치 이름을 적는 것은 번거로우므로 지역 저장소에 반영하지 않은 최신 커밋을 모두 반영하려면 git merge FETCH_HEAD를 사용해주면 된다!
05-3. 협업의 기본 알아보기
앞서 배웠던 내용의 복습이다. collaborator로 등록된 경우 git init 해준 뒤, git config user.name "이름", git config user.email 이메일주소 명령어를 통해 환경을 셋팅할 수 있다.
원격 저장소에 첫 커밋을 push하는 팀장이나, 원격 저장소를 clone해오는 팀원의 사례는 앞서 정리해둔 것과 동일하므로 추가로 작성하지는 않겠다! 하지만 정말 중요한 것은 여러 명이 한 레포에서 작업할 때 최신의 상태를 가져오지 않고 작업한 뒤 push하게 되면 최신 커밋이 반영되지 않은 채로 push했기 때문에 reject되는 경우가 발생할 수 있다. 따라서 첫번째 커밋이 아니라면 항상 pull을 먼저 하는 습관을 들이자!
05-4. 협업에서 브랜치 사용하기
각각 기능을 나눠 개발할 때, 보통 브랜치로 작업한 뒤 master에 합치는 경우가 대부분이다. 한번 살펴보자.
먼저 작업을 수행하기 전에 꼭! git pull을 해준 뒤 시작하자.
f라는 이름으로 브랜치를 만들어 새로운 기능을 개발한다고 가정하자. 다음과 같이 입력하면 이미 f라는 이름의 브랜치가 있다면 그 브랜치로 checkout해준다.
git checkout -b f
vim f4.txt
git add f4.txt
git commit -m "feature4"
git push origin f (원격 저장소 origin에 브랜치 f를 push)
이렇게 브랜치를 push하고 나면 깃허브에서 pull request를 통해 푸쉬한 브랜치를 병합할 수 있다.
브랜치를 눌러 New pull request를 눌러, 메세지를 적절하게 작성한 뒤 Create pull request를 누르면 협업 중인 저장소에 풀 리퀘스트가 전송된다. 이 풀 리퀘스트는 공동 작업자들 누구나 살펴보고 병합할 수 있다. 저장소 파일 위의 pull request 버튼을 누르면 등록된 풀 리퀘스트 목록이 뜬다. 풀 리퀘스트 메세지를 살펴보고 문제가 없다면 Merge pull request 를 통해 병합한다. 필요하다면 메세지를 입력한다. Confirm merge 버튼을 누르면 브랜치 병합이 끝난다. 브랜치가 병합되면 해당 브랜치에 있던 파일이 원격 저장소에 나타난 것을 볼 수 있다.
* 깃허브에서 협업할 때는 보통 작업자마자 브랜치를 만들어 진행하고, 작업 중간중간 풀 리퀘스트를 보내서 master 브랜치에 병합한다. 그래서 깃허브로 협업할 때는 다른 작업자의 변경 내용을 바로 반영하기 위해 항상 pull부터 한 다음 자신의 작업을 진행하도록 하자!
06. 깃허브에서 개발자와 소통하기
(프로필, README 파일 작성은 책을 참고하자. 티스토리에서는 오픈 소스를 다루는 06-3부터 정리)
06-3. 오픈 소스 프로젝트에 기여하기
오픈 소스 프로젝트에 기여하려면 먼저 수정하려는 오픈 소스 저장소를 자신의 저장소로 복제해야 한다. 다른 저장소에 있는 소스를 직접 수정하면 안되기 때문이다. 이를 fork한다고 한다. fork하게 되면 나의 계정에 해당 레포지터리가 복제되어 있을 것이다. 이제 이 레포지터리를 clone해와서 add, commit, push하면 된다. 하지만 이것은 나의 복제된 레포지터리에만 반영되어 있고 원본 레포지터리에는 반영되어 있지 않다. 따라서 오픈 소스 개발자에게 수정한 내용을 원래 소스에 합쳐달라고 요청해야 한다. 이 요청을 풀 리퀘스트라고 부른다.
포크한 자신의 저장소에서 New pull request 버튼을 눌러 수정한 내용을 확인한 뒤 개발자에게 이 수정 사항을 원본 저장소에 반영해달라고 요청할 수 있도록 Create pull request를 누른다. 커밋할 때 입력한 커밋 메세지와 설명이 나타나는데, 원본 개발자에게 문서의 이 부분을 왜 수정했는지 설명하는 내용을 추가로 입력하는 것이 좋다 :) 내용 입력이 끝나면 Create pull request 버튼을 누른다. 이제 화면이 원본 저장소로 바뀌면서 저장소의 개발자와 질문, 답변을 주고받으며 수정한 내용을 원본 소스코드에 반영할지 여부를 결정한다.
06-4. 깃허브에 개인 블로그 만들기
깃허브는 정적인 페이지를 제공할 수 있도록 무료 웹호스팅 기능(GitHub pages) 을 제공한다.
이미 작성한 페이지 소스가 있다면 계정.github.io 라는 이름으로 레포지터리를 만든다. Readme 파일로 이 레포를 초기화한다는 옵션에 반드시 체크하자! 이제 이 레포지터리에 페이지 소스들을 업로드한다. 깃허브 저장소에서 settings에 접속하여 GitHub pages 항목을 살펴보면 홈페이지 주소가 나타날 것이다.
VS Code에서 깃 활용하기
이 부분은 VS code에서 친절하게 버튼으로 다 만들어줘서 보면서 사용하면 될 듯 하다! 잘 모르겠다면 책을 다시 참고하자~!
매번 구글링해가면서 깃을 사용했는데 이번 기회에 책을 읽어가면서 차근차근 개념을 익혀서 좋았다. 얼른 오픈소스에도 기여해보고 브랜치도 잘 써보고! 힘내자
I나 A키를 눌러 텍스트 입력이 끝난 후 파일을 저장할 때는 ESC키를 누르고 콜론(:)을 입력하여 ':wq' (w: 저장, q: 종료) 명령어를 입력한 뒤 엔터를 눌러 저장.
ex 모드에서 사용하는 명령은 콜론(:)으로 시작하고, 자주 사용하는 명령들은 다음과 같다
:w 또는 :write : 편집 중이던 문서를 저장
:q 또는 :quit : 편집기를 종료
:wq (파일명) : 편집중이던 문서를 저장하고 종료. 파일 이름을 함께 입력하면 그 이름으로 저장
:q! : 문서를 저장하지 않고 편집기를 조욜. 확장자가 .swp인 임시 파일이 생성
터미널 창에서 간단히 텍스트 문서의 내용을 확인하기
cat 명령 사용 (concatenate 연쇄하다의 줄임말)
> cat test.txt
02. 깃으로 버전 관리하기
02-1. 깃 저장소 만들기
깃 저장소로 사용할 디렉토리에서 'git init' 명령을 입력하면, 깃을 사용할 수 있도록 해당 디렉터리를 초기화함.
02-2. 버전 만들기
깃에서 버전이란, 문서를 수정하고 저장할 때마다 생기는 것.
깃은 어떻게 파일 이름은 그대로 유지하면서 수정 내역을 기록하는가?
책에 있는 그림은 저작권이 무서워서 직접 ppt로 그린 그림
작업 트리(working tree) : 파일 수정, 저장 등의 작업을 하는 디렉터리
스테이지(stage) : 버전으로 만들 파일이 대기하는 곳
저장소(repository) : 스테이지에서 대기하고 있던 파일들을 버전으로 만들어 저장하는 곳
파일 hello.txt 문서를 수정하고 저장하면, 그 파일은 작업 트리에 존재. 수정한 hello.txt 파일을 버전으로 만들고 싶다면 스테이지에 넣음. 파일 수정을 끝내고 스테이지에 다 넣었다면 버전을 만들기 위해 깃에게 commit 명령을 내림. commit 명령을 내리면 새로운 버전이 생성되면서 스테이지에 대기하던 파일이 모두 저장소에 저장.
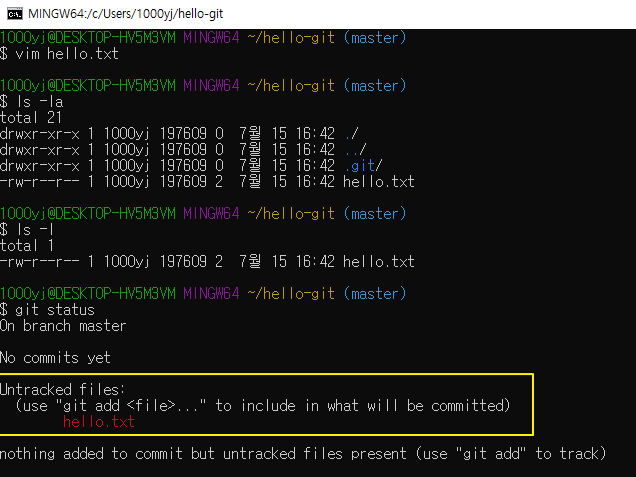
vim으로 실습
hello.txt 파일 생성 후 상태 보기
* 깃에서는 아직 한번도 버전 관리하지 않은 파일을 untracked files라고 부름
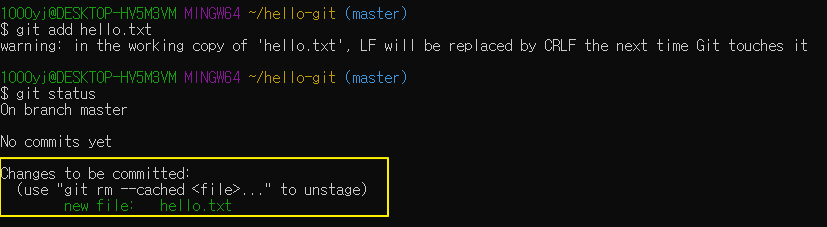
작업 트리에서 파일을 만들거나 수정했다면 스테이지에 수정한 파일을 추가하자!
깃에서 스테이징할 때 사용하는 명령은 'git add'
git add hello.txt 명령어 수행 후 상태 보기
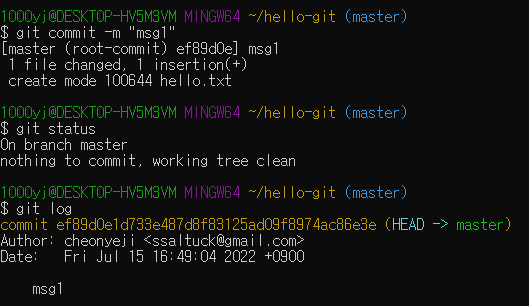
스테이지에 올라온 파일 커밋하기 (버전 만들기)
깃에서 파일을 커밋하는 명령은 'git commit'
'git commit -m "msg1" ' 과 같이 -m 옵션으로 커밋과 함께 저장할 메시지를 적을 수 있음
커밋이 제대로 되었는지 git log로 확인해보자
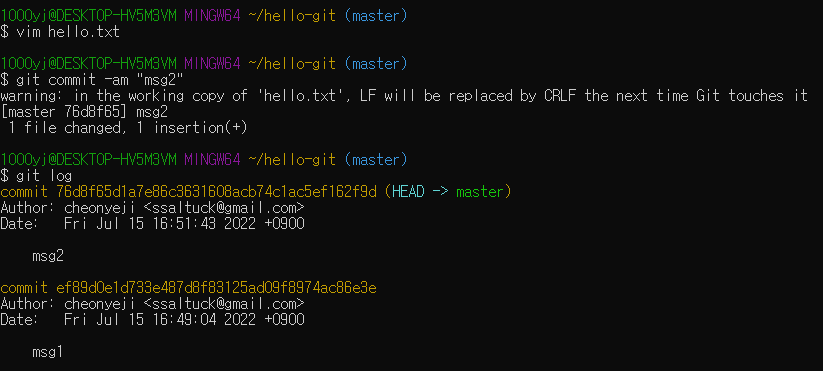
스테이징과 커밋을 한꺼번에 처리하자 - git commit -am
* 한 번이라도 커밋한 적이 있는 파일을 다시 커밋할 때만 사용 가능
add와 commit을 동시에 처리하는 commit -am 옵션
02-3. 커밋 내용 확인하기
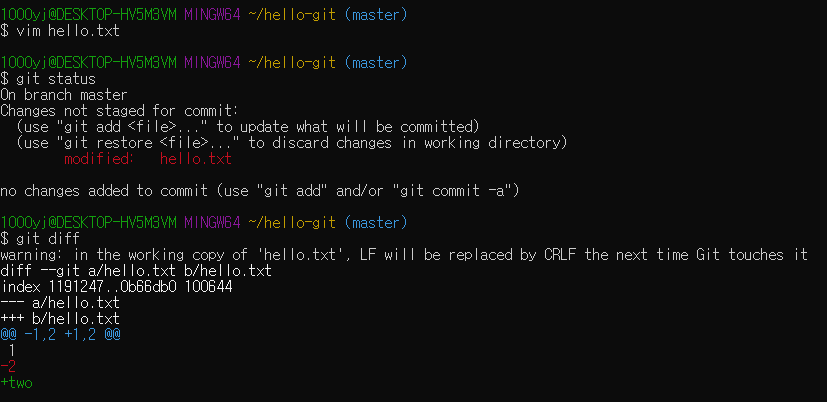
git log를 사용하여 커밋 메세지를 확인하거나, 변경 사항을 확인할 수 있는 명령어인 git diff를 사용하자
hello.txt를 수정한 뒤 git diff로 확인해본 모습
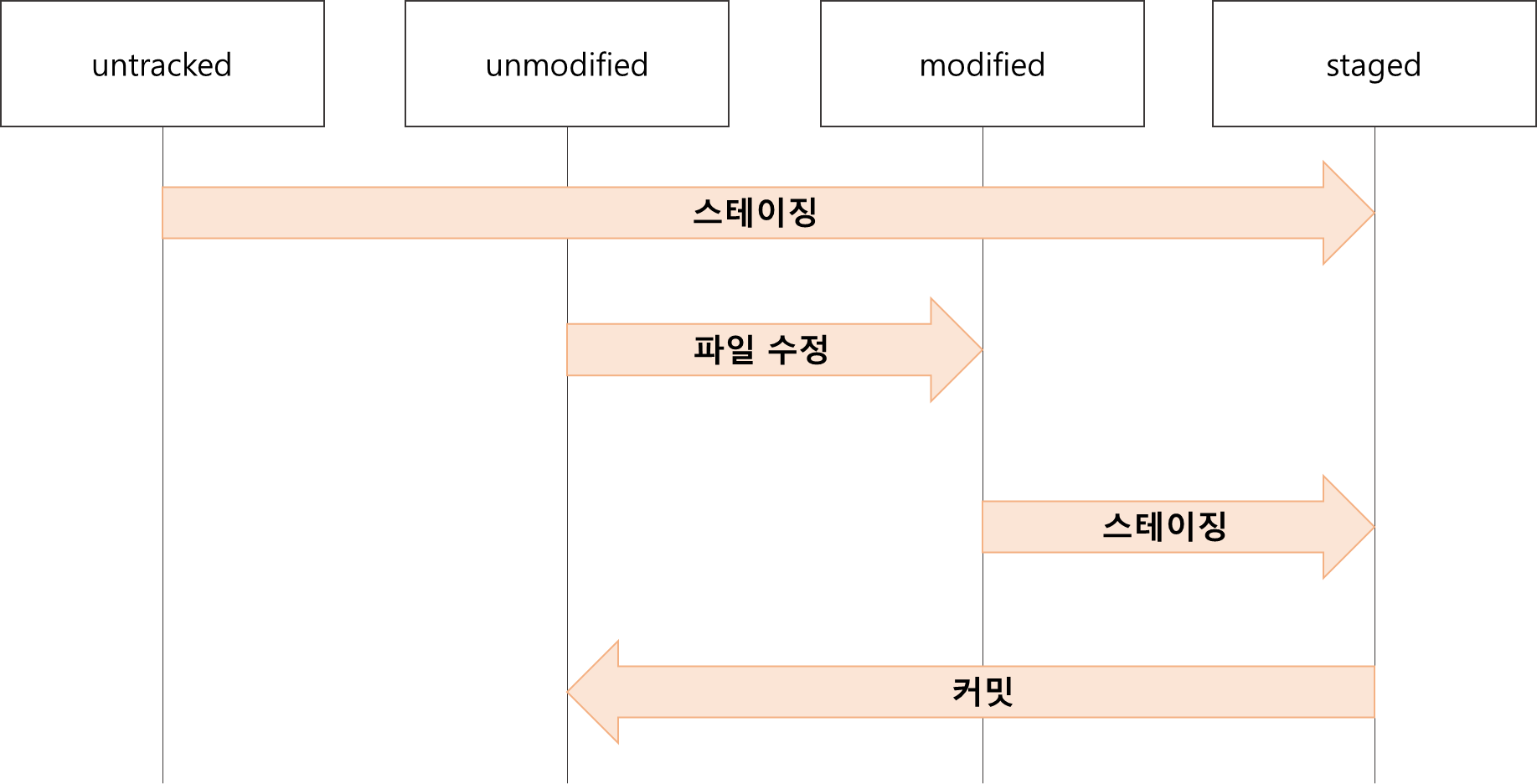
02-4. 버전 만드는 단계마다 파일 상태 알아보기
깃에서는 버전을 만드는 각 단계마다 파일 상태를 다르게 표시하므로, 파일의 상태를 이해하면 조금 더 수월!
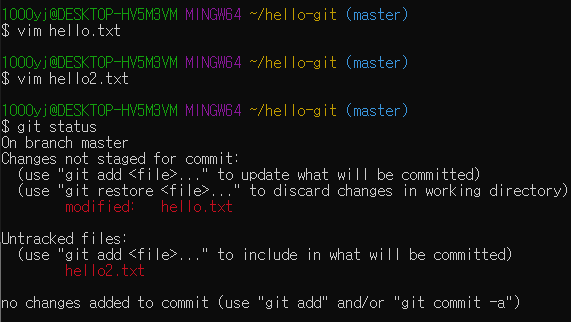
tracked : 한번이라도 커밋을 한 파일이어, 수정여부를 계속 추적중인 파일
untracked : 한번도 깃에서 버전 관리를 하지 않아 수정 내역을 추적하지 않는 파일
tracked, untracked 파일들
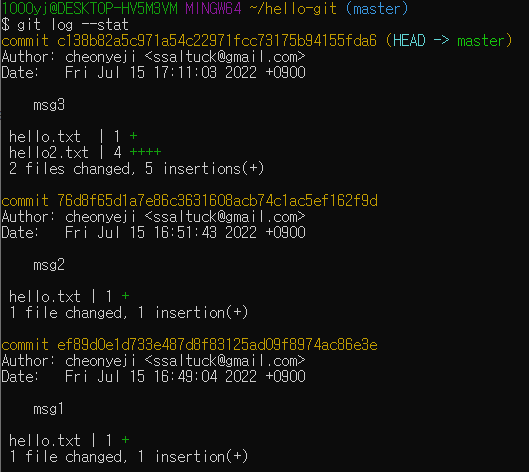
각 커밋 메세지가 어떤 파일에 관련된 것인지 살펴보려면 'git log --stat' 옵션을 사용한다.
git log --stat 옵션
tracked 파일의 상태들
unmodified : 수정되지 않은 상태
modified : 파일이 수정만 된 상태
staged : 수정 뒤 스테이지에 올린 상태. (커밋 직전 단계)
git status 명령으로 확인 가능한 파일 상태들
* 방금 커밋한 메세지를 수정하려면 git commit --amend 명령어를 사용하면 됨
vim 편집기로 커밋 메세지를 수정할 수 있다
02-5. 작업 되돌리기
작업 트리에서 수정한 파일 되돌리기 - git restore (교재에서는 checkout을 소개하나, git 2.23 버전부터 기능이 세분화됨)
스테이징 되돌리기 - git restore --staged 파일 이름 (교재에서는 reset HEAD을 소개하나, git 2.23 버전부터 기능이세분화됨)
최신 커밋 되돌리기 - git reset HEAD^ (이전 버전으로 아예 되돌리는 방법에는 revert를 더 권장한다고 한다. reset은 커밋 자체를 삭제해버리는 것이고, revert는 되돌리는 버전을 새로 커밋하는 것)
* 혼자 쓰는 깃이 아니라면 reset --hard는 지양하자...
커밋 삭제하지 않고 되돌리기 - git revert 커맷해시
나중에 사용할 것을 대비하여 커밋을 되돌리더라도 취소한 커밋을 남겨둘 때 사용
revert 명령을 실행할 떄는 커밋 메세지를 입력할 수 있도록 편집기가 열림. 커밋 메세지 맨 위에는 어떤 버전을 revert 했는지 나타나며, 추가로 남겨둘 내용이 있다면 입력하고 저장하기.
* reset의 경우에는 되돌아갈 커밋 해시를, revert의 경우에는 취소할 커밋 해시를 지정함!
03. 깃과 브랜치
브랜치란, 커밋을 가리키는 포인터와 비슷하다고 이해하자!
깃으로 버전 관리를 시작하면 기본적으로 master라는 브랜치가 생성되며, 사용자가 커밋할 때마다 master 브랜치는 최신 커밋을 가리킴.
새 브랜치를 만들면 기존에 저장한 파일을 master 브랜치에 그대로 유지하면서 기존 파일 내용을 수정하거나 새로운 기능을 구현할 파일을 만들 수 있음.
새 브랜치에서 원하는 작업을 다 끝냈다면 새 브랜치에 있던 파일을 원래 master 브랜치에 합칠 수 있음(merge)
새 브랜치 만들기
깃에서 브랜치를 만들거나 확인하는 명령 : git branch
새로운 브랜치를 만들 때 : git branch 브랜치명
브랜치 사이 이동하기 - git checkout
브랜치 분기
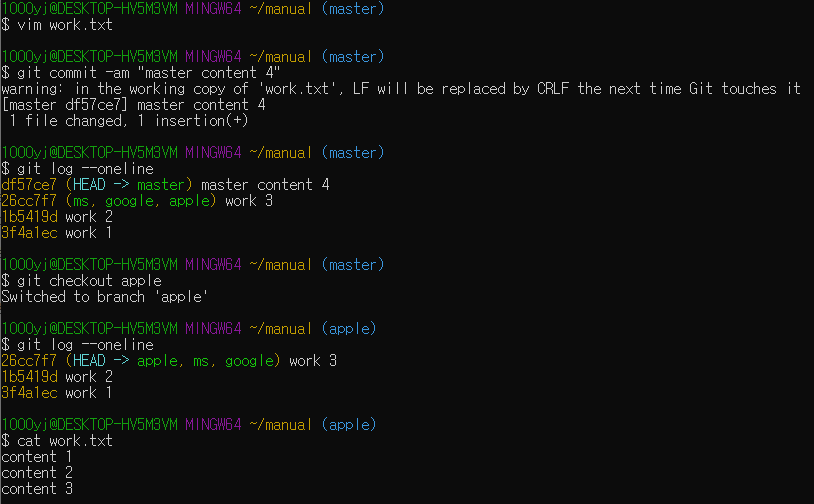
git checkout 브랜치명 을 사용하면 해당 브랜치 내에서 발생한 부분까지만 볼 수 있다. (현재 master에는 master content 4라는 커밋이 하나 더 있으나 apple 브랜치에서는 알 수 없다)
* git log --oneline : 로그를 한줄로 보여줌. 간편하다!
03-3. 브랜치 정보 확인하기
여러 브랜치에서 각각 커밋이 이루어질 때 커밋끼리 어떤 관계를 하고 있는지 확인하는 방법과 브랜치 사이의 차이점을 확인하는 방법을 알아보자.
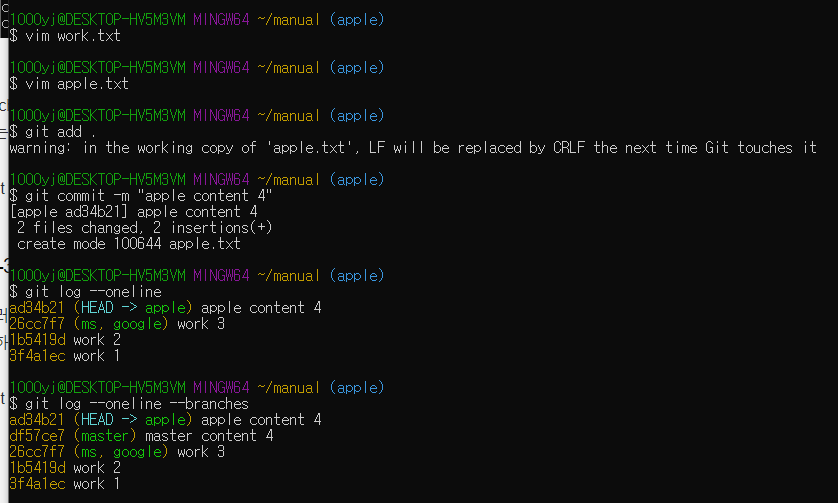
* git log --oneline --branches : 각 브랜치의 커밋을 함께 볼 수 있음
각 브랜치별로 커밋상태가 다른 상황
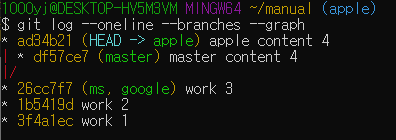
* 브랜치와 커밋의 관계를 좀 더 보기 쉽게 그래프 형태로 표시하려면 --graph 옵션을 붙여 사용하면 된다.
git log --oneline --branches --graph
쓰다보니까 ,,, sourceTree 쓰고싶어졌다,,, 그치만 리눅스 익숙해질 겸 힘내보자,,,!
브랜치 사이의 차이점 알아보기
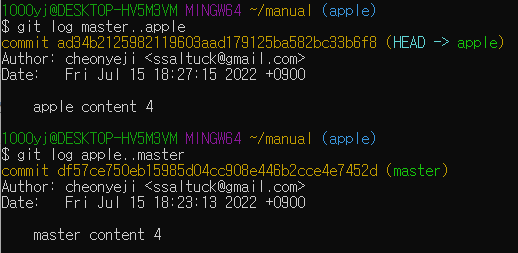
브랜치마다 커밋이 점점 쌓여갈수록 브랜치 사이에 어떤 차이가 있는지 일일이 확인하기 어려워질 수도 있다. 이럴 때는 브랜치 이름 사이에 마침표 두 개(..)를 넣는 명령으로 차이점을 쉽게 확인할 수 있다.
* 마침표 왼쪽에 있는 브랜치를 기준으로 오른쪽 브랜치와 비교한다.
master <-> apple 브랜치 비교
03-4. 브랜치 병합하기
만들어진 각 브랜치에서 작업을 하다가 어느 시점에서는 브랜치 작업을 마무리하고 기존 브랜치와 합해야 하는 경우가 생긴다. 이를 브랜치 병합(merge)라고 한다.
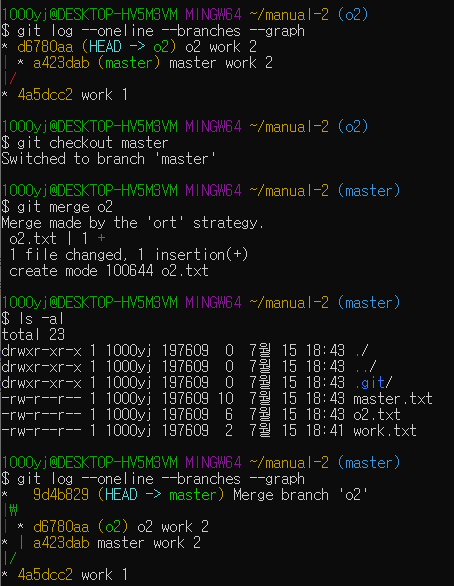
master 브랜치에서 work.txt 파일을 만들고 커밋한 뒤 새로운 branch o2를 만들어보자.
master 브랜치에 master.txt 파일을 만들고 커밋한다.
o2 브랜치로 체크아웃한 뒤, o2.txt라는 파일을 만들고 커밋한다.
o2 브랜치에서 작업이 모두 끝났다고 가정하고, o2 브랜치의 내용을 master 브랜치로 병합해보자.
먼저 master 브랜치로 체크아웃해야한다.
브랜치를 병합하려면 git merge 뒤에 가져올 브랜치 명을 적는다. "git merge o2"
브랜치를 합쳐보자!
같은 문서의 다른 위치를 수정했을 때 병합하기 -> 알아서 잘 해준다 깃 최고!
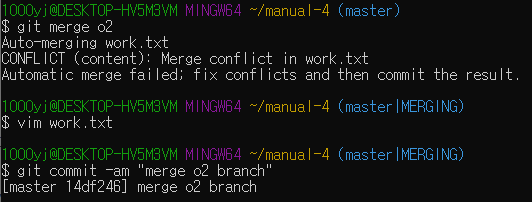
같은 문서의 같은 위치를 수정했을 때 병합하기 -> 브랜치 충돌(conflict) 발생...!
work.txt의 동일한 부분을 수정했더니 발생한 conflict
conflict가 발생한 부분의 코드를 원하는 방향으로 수정한 뒤, 다시 commit 해주면 에러는 사라진다.
병합이 끝난 브랜치 삭제하기 - git branch -d 브랜치명
브랜치를 병합한 후 더 이상 사용하지 않는 브랜치는 깃에서 삭제할 수 있다. 단, 이렇게 브랜치를 삭제하더라도 이 브랜치가 완전히 지워지는 것은 아니며, 다시 같은 이름의 브랜치를 만들면 예전 내용을 다시 볼 수 있다. (흐름에서 감준다고 생각하자)
03-5. 브랜치 관리하기
수정 중인 파일 감추기 및 되돌리기 - git stash
파일을 수정하고 커밋하지 않은 상태에서 급하게 다른 파일을 커밋해야 하는 경우!
여러 파일을 수정하고 따로 보관할 수 있으며, 감춘 파일은 stash list에서 확인 가능하다. (stack 방식)
즉,알고리즘이란 입력값을 출력값의 형태로 바꾸기 위해 어떤 명령들이 수행되어야 하는지에 대한규칙들의 순서적 나열
알고리즘을 평가할 때는정확성도 중요하지만,효율성도 중요
3. 배열
1) 컴파일링
make나 clang을 사용해서 프로그램을 실행할 때 아래 네 개의 단계를 거칩니다.
전처리
컴파일링
어셈블링
링킹
우리가 명령어를 실행할 때 정확히 어떤 일이 일어나는지 알아보도록 하겠습니다.
전처리(Precompile)
컴파일의 전체 과정은 네 단계로 나누어볼 수 있습니다. 그 중 첫 번째 단계는 전처리인데, 전처리기에 의해 수행됩니다. # 으로 시작되는 C 소스 코드는 전처리기에게 실질적인 컴파일이 이루어지기 전에 무언가를 실행하라고 알려줍니다.
예를 들어, #include는 전처리기에게 다른 파일의 내용을 포함시키라고 알려줍니다. 프로그램의 소스 코드에 #include 와 같은 줄을 포함하면, 전처리기는 새로운 파일을 생성하는데 이 파일은 여전히 C 소스 코드 형태이며 stdio.h 파일의 내용이 #include 부분에 포함됩니다.
컴파일(Compile)
전처리기가 전처리한 소스 코드를 생성하고 나면 그 다음 단계는 컴파일입니다. 컴파일러라고 불리는 프로그램은 C 코드를 어셈블리어라는 저수준 프로그래밍 언어로 컴파일합니다.
어셈블리는 C보다 연산의 종류가 훨씬 적지만, 여러 연산들이 함께 사용되면 C에서 할 수 있는 모든 것들을 수행할 수 있습니다. C 코드를 어셈블리 코드로 변환시켜줌으로써 컴파일러는 컴퓨터가 이해할 수 있는 언어와 최대한 가까운 프로그램으로 만들어 줍니다. 컴파일이라는 용어는 소스 코드에서 오브젝트 코드로 변환하는 전체 과정을 통틀어 일컫기도 하지만, 구체적으로 전처리한 소스 코드를 어셈블리 코드로 변환시키는 단계를 말하기도 합니다.
어셈블(Assemble)
소스 코드가 어셈블리 코드로 변환되면, 다음 단계인 어셈블 단계로 어셈블리 코드를 오브젝트 코드로 변환시키는 것입니다. 컴퓨터의 중앙처리장치가 프로그램을 어떻게 수행해야 하는지 알 수 있는 명령어 형태인 연속된 0과 1들로 바꿔주는 작업이죠. 이 변환작업은 어셈블러라는 프로그램이 수행합니다. 소스 코드에서 오브젝트 코드로 컴파일 되어야 할 파일이 딱 한 개라면, 컴파일 작업은 여기서 끝이 납니다. 그러나 그렇지 않은 경우에는 링크라 불리는 단계가 추가됩니다.
링크(Link)
만약 프로그램이 (math.h나 cs50.h와 같은 라이브러리를 포함해) 여러 개의 파일로 이루어져 있어 하나의 오브젝트 파일로 합쳐져야 한다면링크라는 컴파일의 마지막 단계가 필요합니다. 링커는 여러 개의 다른 오브젝트 코드 파일을 실행 가능한 하나의 오브젝트 코드 파일로 합쳐줍니다. 예를 들어, 컴파일을 하는 동안에 CS50 라이브러리를 링크하면 오브젝트 코드는 GetInt()나 GetString() 같은 함수를 어떻게 실행할 지 알 수 있게 됩니다.
이 네 단계를 거치면 최종적으로 실행 가능한 파일이 완성됩니다.
2) 디버깅
버그와 디버깅
버그(bug)는 코드에 들어있는 오류입니다. 버그로 인해 프로그램의 실행에 실패하거나 프로그래머가 원하는 대로 동작하지 않게 됩니다. 버그를 만들고 싶지 않겠지만 모든 프로그래머들은 버그와 마주하게 되어있습니다. 디버깅(debugging)은 코드에 있는 버그를 식별하고 고치는 과정입니다. 프로그래머는 디버거라고 불리는 프로그램을 사용하여 디버깅을 하게 됩니다.
디버깅의 기본
디버거는 프로그램을 특정 행에서 멈출 수 있게 해주기 때문에 버그를 찾는데 도움이 됩니다. 프로그래머는 멈춰진 그 지점에서 무슨 일이 일어나는지 볼 수 있습니다. 프로그램이 멈추는 특정 지점을 중지점이라고 합니다. 또한 프로그래머가 프로그램을 한번에 한 행씩 실행할 수 있게 해줍니다. 이로써 프로그래머는 프로그램이 내리는 모든 결정들을 단계별로 따라갈 수 있게 됩니다.
help50
아래와 같이 make 앞에 help50 을 붙여서 실행하면 다시 컴파일시 생기는 오류를 해석해줍니다.
help50 make 파일이름
debug50
CS50 IDE를 사용하면debug50이라는 프로그램도 사용할 수 있습니다.
아래와 같이 소스 코드에 직접 브레이크포인트를 지정하고 소스파일을 컴파일한 후에“debug50 파일명”으로 실행하면, 오른쪽 패널을 통해 변수의 값을 확인하거나 브레이크포인트부터 한 줄씩 코드를 실행해 볼 수 있습니다.
디버깅 종료를 위해서는Ctrl + c를 누르면 됩니다.
7) 문자열의 활용
strlen은 문자열의 길이를 알려주는 함수로, string.h 라이브러리 안에 포함되어 있습니다.
ctype 라이브러리에toupper()이라는 함수는 사용자로부터 문자열을 입력받아 대문자로 바꿔주는 함수입니다.
문자열 관련된 라이브러리는 string.h고 문자 관련된 라이브러리는 ctype.h이니, 두 라이브러리 내 구현된 함수를 활용하도록 합시다.
8) 명령행 인자
make나 clang과 같은 프로그램을 실행할 때 컴파일하고자 하는 코드 외에도 컴파일 후 저장하고자 하는 파일명과 같이 추가적인 정보를 함께 줄 수도 있습니다. 이런 정보들을 명령행 인자 라고 부릅니다.
main() 안에 기계적으로 void 라고 입력하는 대신 아래 코드와 같이 argc, argv 를 정의해보겠습니다.
하드웨어가 시스템의 수행 흐름을 바꾸기 위해 발생하는 것. 트랩(예외, exception)의 경우 소프트웨어가 발생하는 인터럽트이다. 인터럽트가 발생되면 CPU는 현재 수행중인 작업을 멈추고 운영체제 내에 있는 특정 코드를 실행한다. 이 실행이 끝나면 다시 멈춘 작업을 재개한다.
인터럽트는 1) 현재 작업을 멈추고, 현재 상태를 보관 2) 인터럽트의 종류 분석 3) 특정 인터럽트 수행 4) 보관된 상태를 원상복귀하고 멈춘 작업을 재개하는 과정을 통해 실행된다.
DMA 존재 이유에 대해서 설명하세요.
I/O (입출력)에는 두 가지 형태가 있다.
- 동기식 입출력 (synchronous I/O) : 입출력이 시작되면 요청한 프로세서는 입출력이 완료될 때까지 기다린다.
- 비동기식 입출력 (asynchronous I/O) : 요청한 프로세서는 입출력이 완료될 때까지 기다리지 않고 계속 다른 작업을 수행한다.
속도가 느린 입출력 장치는 하나의 입력을 받은 후 다음 입력까지 CPU는 다른 유용한 작업을 할 수 있다. 그러나 반대로 입출력 장치의 속도가 빠르면 인터럽트가 너무 빈번하게 발생하여 CPU가 다른 유용한 작업을 할 시간이 적다. 이것을 해결하기 위해 사용하는 기법이 DMA(Direct Message Access)이다. DMA 방식에서 장치 제어기(디스크, 오디오 장치를 관리)는 데이터 블록을 CPU의 관여 없이 직접 주기억장치로 이동하며, 인터럽트는 바이트 단위가 아닌 블록 단위로 발생한다.
즉, DMA란 CPU의 개입 없이 입출력장치와 주기억장치의 데이터 전송이 이루어지는 방법으로, 입출력을 위한 인터럽트 발생 횟수를 최소화하여 컴퓨터 시스템의 효율을 높이기 위해 필요하다.
함수호출과 시스템 콜의 차이에 대해서 설명하세요.
함수 호출이란 자신이 직접 작성하거나 라이브러리에 저장된 함수를 호출하는 것이다.
* 라이브버리 함수들에는 프로그래밍 언어에서 제공하는 기본 함수들과 컴파일러별로 추가적으로 제공하는 API들이 속한다. 따라서 프로그램 내부에서 메모리 할당/해제가 가능하다.
시스템 콜(시스템 호출)의 기본적인 정의는 프로세스와 운영체제 간 인터페이스를 제공해주는 것이다. 즉 운영체제의 커널이 제공하는 서비스에 접근하기 위한 수단이라고 이해할 수 있다. 시스템 콜의 경우 프로세스 제어, 파일 관리, 장치 관리, 정보 유지보수, 통신 등 다양한 기능을 수행하기 위해 운영체제에 미리 정의가 되어 있는 함수를 사용하는 것이다.
인터럽트와 시스템 콜의 차이에 대해서 설명하세요.
인터럽트는 하드웨어가 시스템의 수행 흐름을 바꾸기 위해 사용하는 것이고, 트랩의 경우 소프트웨어가 발생하는 인터럽트이다. 소프트웨어는 시스템 콜이라는 연산을 통해 트랩을 발생시킨다.
시스템 콜의 경우 프로그램이 커널에서 서비스를 요청할 수 있도록 하는 방법이며, 인터럽트는 CPU에게 특정 일을 즉각적으로 수행하도록 고지하는 이벤트이다. (하드웨어 인터럽트, 소프트웨어 인터럽트라는 개념으로 접근해서 이해하면 조금 더 수월할 듯 하다)